이번 강좌에서는 기존 3편에 이어서 ".find"문을 활용하여 크롤링을 해볼 것입니다. 이번 강좌는 기존 2편, 3편을 이어서 진행하는 것이기 때문에 기존 강좌를 보고 오시는 것을 추천드립니다.
.find 문에 대해 알아보자.
우선 시작전에 ".find" 문에 대해 알아보아야 합니다. 기존 시간에는 ".select"를 통해 파싱을 할 수 있었고, ".find" 를 통해 크롤링을 할 수 있다고 했었습니다. 우선 ".find" 방식과 ".select" 방식의 차이점으로 보자면 ".find"는 하나하나 직접 찾아 작성하기 때문에 대부분 오차율이 적은 편입니다. (사이트가 형식이 바뀌게 될 경우 ".select", ".find" 방식 둘 다 다시 짜줘야 한다는 점 참고하시기 바랍니다.) 대신, 코드가 상당히 길어진다는 단점이 있습니다.
find문의 구성은 이렇게 되어 있습니다.
soup.find("열린태그", {"속성":"속성값"})기존 3편에서 말했듯이 열린태그와 속성 , 속성 값을 통해 쉽게 찾을 수 있습니다.
<span class="Python3">None</span>이렇게 구성된 사이트를 위 find 형태를 사용해서 불러오기 전에, 우선 저 값을 BeautifulSoup를 통해 변환을 해야 합니다.
from bs4 import BeautifulSoup
#HTML안에 위 내용이 들어가 있다고 가정.
soup = BeautifulSoup(HTML,"html.parser")그다음 아래의 방식으로 값을 구할 수 있습니다. soup라는 안에 soup 형태의 변수를 넣게 된다면
soup.find("span", {"class":"Python3"})이렇게 불러올 수 있습니다. 이렇게 되면 "<span class="Python3">None</span>"이라는 값이 반환되게 됩니다.
잠시만요? 근데 안에 있는 None 값만 구하고 싶은데요?
그럴 경우 find 뒷쪽에 .text를 붙여서 쉽게 값을 불러오실 수 있습니다.
soup.find("span", {"class":"Python3"}).text이렇게 하시면 저 HTML 코드들은 모두 제외되고 우리 눈에만 보여주는 값 혹은 안에 들어 있던 정보만 불러오게 됩니다.
만약에 기존처럼 아래처럼 html 코드가 복잡하게 구성되어 있다면 어떻게 해야 할까요?
사실 html 웹사이트는 저렇게 단 줄로 끝나지 않습니다. 우리에게 많은 정보를 알려주기 위해 상당히 복잡한 코드를 가지고 있습니다. 만약 아래처럼 span안에 또 다른 span이 있을 경우 어떻게 해야 할까요?
<span class="First_Tag">
<span class="Second_Tag">undefined</span>
</span>이 경우 두 가지 방법이 있습니다. 우선 위에 설명되어 있는 것처럼 soup를 먼저 지정합니다.
from bs4 import BeautifulSoup
#HTML안에 위 내용이 들어가 있다고 가정.
soup = BeautifulSoup(HTML,"html.parser")
일단 본인은 정확도를 원하시다 하시면, find를 연속적으로 사용하시면 됩니다. find는 위에서 설명했듯이 직접 하나하나 다 찾아줄 수 있기 때문에 오차율이 적다는 겁니다.
soup.find("span", {"class":"First_Tag"}).find("span", {"class":"Second_Tag"}).text그러나, 이 방식대로 사용하다 보면 코드가 상당히 길어진다는 단점이 있습니다. 그래서 가능하면 아래처럼 단축해서 사용하실 수도 있습니다.
soup.find("span", {"class":"Second_Tag"}).text위 방식을 사용하시면 우리는 undefined 라는 값을 반환받을 수 있습니다.
단지, 우리는 코드를 줄이기 위해 이렇게 class라는 속성에 값이 First_Tag인 경우를 잡지 않고 바로 Second_Tag라는 값을 찾게 설정할 수 있습니다. 그러나 저 Second_Tag라고 하는 속성 값이 많을 경우 위 방식이 아닌 그 위쪽에 있는 방식을 사용해야 한다는 점 참고하시기 바랍니다.
.find 말고 .find_all 에 대해 알아보자
.find는 첫 번째 값만 불러옵니다. 만약에 아래처럼 두 번째나 그 이상을 구하고 싶다면 어떻게 해야 할까요?
<div class="First_Tag">
<span class="Second_Tag">HTML</span>
<span class="Second_Tag">CSS</span>
<span class="Second_Tag">JavaScript</span>
<span class="Second_Tag">PHP</span>
<span class="Second_Tag">Node.JS</span>
</div>이렇게 생긴 웹사이트가 있다고 가정해 봅니다. 우리는 "PHP"라는 값을 반환받고 싶지만 find를 사용할 경우 "HTML"를 반환받게 됩니다. 이럴 경우 우리는 어떻게 해야 할까요? 이럴 경우 우리는 .find_all를 사용해야 합니다
from bs4 import BeautifulSoup
#HTML안에 위 내용이 들어가 있다고 가정.
soup = BeautifulSoup(HTML,"html.parser")시작 전 soup를 먼저 지정하고 시작합니다.
.find_all은 기존 .find와 달리 만약에 열린 태그, 속성, 속성 값이 같을 경우 모두 배열에 저장하게 됩니다.
이 경우 모든 Second_Tag가 First_Tag라는 곳에 있기 때문에 First_Tag를 굳이 찾아줄 필요는 없습니다.
soup.find("span", {"class":"Second_Tag"})이와 달리 저 ".find"를 ".find_all"를 사용하면 어떻게 될까요?
soup.find_all("span", {"class":"Second_Tag"})이렇게 되면 우리는 배열 안에 저장하게 되어 아래처럼 반환 되게 됩니다.
["<span class="Second_Tag">HTML"</span>,
"<span class="Second_Tag">CSS"</span>,
"<span class="Second_Tag">JavaScript</span>",
"<span class="Second_Tag">PHP</span>",
"<span class="Second_Tag">Node.JS</span>"]사실은 한 줄 안에 저 내용이 모두 포함되어서 나오게 되지만 그러면 예제가 너무 길어지게 되어서 위처럼 작성하였습니다. 우리는 원하는 값을 변수명[위치] 방식을 사용하여 꺼낼 수 있습니다.
soup.find_all("span", {"class":"Second_Tag"})[3].text를 사용하게 된다면 우리가 원하는 "PHP"값을 반환받게 됩니다.
이제 바로 써볼까요?
우선 우리가 필요한 데이터를 먼저 정해야 합니다. 그럼 이번에는 find를 활용해서 네이버에서 강남구 날씨를 불러오도록 해보겠습니다.
우선 모듈을 불러와야겠죠? 우리는 requests 모듈과 bs4 모듈만 있으면 충분히 개발할 수 있습니다.
그리고 requests를 통해 강남구 날씨를 불러오고 soup 변환작업까지 끝났다는 상태에서 작업해보겠습니다.
import requests
from bs4 import BeautifulSoup #bs4 모듈안에 있는 BeautifulSoup를 불러옴.
resp = requests.get("https://search.naver.com/search.naver?query=강남구+날씨")
soup = BeautifulSoup(resp.text,"html.parser")
저는 크롬을 이용해서 크롤링할 정보를 구해옵니다. 이건 여러분들이 본인이 알맞다는 개발자 도구를 구해서 하시면 됩니다. 크롬을 이용하시면 그 값이 어디 있는지 쉽게 볼 수 있기 때문에 저로썬 추천합니다.
우리가 뜯어볼 사이트의 구조는 이렇게 생겼습니다.

(이게 알고 보니 네이버 UI가 변경됐다는 것을 저는 이제 알았습니다 ㅎㅎ) F12를 눌러 개발자 도구를 엽니다.
F12키 말고 우클릭 -> 검사(N)를 통하여 활성화할 수 있습니다.

우리가 필요한 값은 날씨 정보 오른쪽에 있는 "서울특별시 강남구 역삼동"과, 아래 "12℃", 그리고 그 위에 적혀있는 문구를 가져와 보도록 하겠습니다.
우측 Elements 왼쪽으로 두 칸에 있는 첫 번째 아이콘을 통해 우리는 쉽게 불러올 수 있습니다.

이렇게 우리가 찾고자 하는 내용을 좌 클릭하게 된다면 해당 값의 위치를 알 수 있습니다. 그러나 이렇게 복잡한 값을 한 번에 적는 것은 비효율적이며, 우리는 저 날씨 정보 박스 값 안에 있는 내용을 먼저 저장하도록 하겠습니다.

이 박스의 태그는 "section"이며, 속성과 그 값은 "class"와 "sc_new cs_weather _weather"이군요. 그러면 이를 find를 활용하여 box라는 변수 안에 저장해보도록 하겠습니다.
box = soup.find("section",{"class":"sc_new cs_weather _weather"})이렇게 box안에다가 값을 넣어보았습니다. 그러면 box 안에는 저 날씨 정보에 대한 값만 들어가게 됩니다.
그다음 우리가 구해볼 값은 "서울특별시 강남구 역삼동"이라는 정보입니다.
위에 알려주었던 Elements 왼쪽에 있는 첫 번째 버튼을 누릅니다.
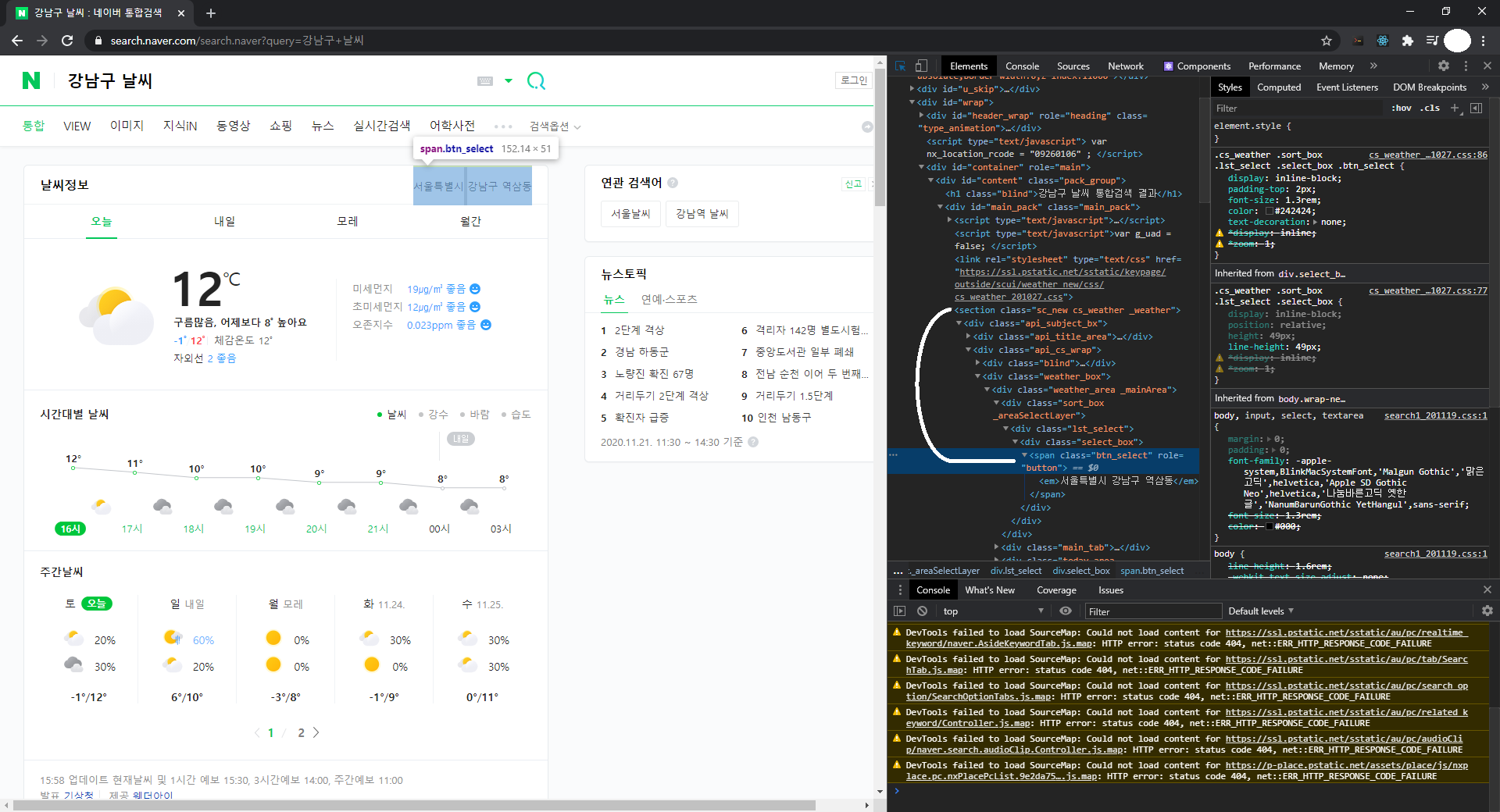
설마 저 하나하나 태그를 적어야 하는 건가요? 아닙니다. 그냥 스킵하셔도 됩니다.
저 값이 태그 em이라는 곳 안에 있지만 오차율을 줄이기 위해 위에 있는 태그를 사용 후에 em 태그를 불러오도록 합시다. 여기서 왜 오차율이 발생하냐면 em이라는 태그 하나만 있으면 다른 여러 em태그도 잡히기 때문입니다.
위 box 모듈에는 날씨정보 박스 안에 있는 값들이 저장되어 있으니 이어나가서 사용합니다.
우선 그 상위 코드의 태그는 "span"이고, 속성에는 "role"과 "class"가 있으나 편의상 "class"를 사용하겠습니다. 그리고 속성 값은 "btn_select" 인 것을 확인할 수 있습니다.
local_name = box.find("span",{"class":"btn_select"}).find("em").text참고로 find는 계속 이어나갈 수 있기 때문에 이렇게 작성하시면 local_name 안에 "서울특별시 강남구 역삼동"이라는 내용이 저장되게 됩니다.
다음은 "12℃"를 불러와보도록 하겠습니다.

다시 확인해본 결과 태그는 "span", 속성과 속성 값은 각각 "class" 그리고 "todaytemp"네요. 그러면 아래처럼 작성하시면 됩니다.
temp = box.find("span",{"class":"todaytemp"}).text이렇게 작성하시면 temp라는 변수 안에 현재 강남구의 현재 온도가 저장되게 됩니다.
마지막으로 우리가 구해볼 값은 "구름많음, 어제보다 0℃ 높아요." 라는 내용입니다.

이번에는 "p"라고 하는 태그에 "class"라는 속성, 그리고 "cast_txt"라는 속성 값을 찾을 수 있습니다.
그런데 말입니다. "컨트롤키 + F"를 통해 저 "cast_txt"가 여러 개 있군요.

하지만 우리는 첫 번째 값이 필요하긴 하지만 그래도 ".find_all"을 사용해서 잡아보도록 하겠습니다.
content = box.find_all("p",{"class":"cast_txt"})[0].text이렇게 여러 개의 찾은 값 중에서 첫 번째 값만 불러온 후 그 내용을 content라는 변수 안에 저장하였습니다.
그래서 결론은 무엇일까요? 과연 우리가 똑바로 구했는지 확인해보아야 합니다. print를 활용하여 제대로 된 값이 나왔는지 확인해봅시다. 저는 Visual Studio Code 디버그 모드로 확인해 보겠습니다.


왼쪽 사진과 오른쪽 사진을 비교해보시기 바랍니다. 잘 나오는 것 같네요. 근데 어디 익숙하지 않나요?
네 그렇습니다. 지난 1편에서 보여드린 예제와 비슷합니다. 이렇게 쉽게 크롤링이라는 것을 할 수 있습니다.
# ".select"으로 하는것은 크롤링이 아닌 파싱이라고 합니다. 강의중에선 ".select"도 크롤링하는거라고 하지만 파싱이라고 하니 오해하지 마시기 바랍니다.
이번 강좌에서는 ".find"문을 활용한 크롤링에 대해 알아보았습니다. 다음에는 크롤링 강좌의 마지막이 될 수 있군요.. 다음 시간에는 크롤링이 아닌 파싱을 활용한 ".selcet" 문을 활용하여 위와 똑같이 구해보도록 하겠습니다. 이 긴 글을 읽어주느라 수고하셨습니다.
'개발 강좌 > 크롤링 강좌' 카테고리의 다른 글
| 크롤링 05 | select를 사용하여 값을 불러오자 (0) | 2020.12.20 |
|---|---|
| 크롤링 03 | 크롤링을 하기전에 알아야 할것 (0) | 2020.12.06 |
| 크롤링 02 | 파이썬을 통하여 html를 불러오자. (7) | 2020.11.29 |
| 크롤링 01 | 크롤링이란? (0) | 2020.11.22 |